concurrentSkipListMap의 발전 과정
이번 포스팅은 concurrentSkipListMap가 JDK별로 어떻게 발전해 왔는가에 대해 알아보기 위해 작성되었습니다. 사실 이런 자료구조를 사용해 본 적도 없는 저 였기에,
조금은 미흡할지도 모르지만, 이번 기회를 통해 다같이 concurrentSkipListMap에 대해 알아보는 시간이 되었으면 좋겠습니다.
배경 지식
먼저 concurrentSkipListMap가 나오게 된 배경에 대해 알아보겠습니다. 우선 웹에서 얻은 정보에 의하면, 기존에 존재하던 Syncronized Collection을 사용하면 모든 메소드들이 전부 키를 사용하여
locking되기 때문에 완전한 Thread-Safety는 보장이 되지만 그에 따른 비용이 발생하였습니다. 또한 이 때문에 데드락이 발생할 수 있는 여지가 생기며, 여러 쓰레드가 대기 상태에 머무를 수 있습니다.
하지만 Concurrent Collection은 멀티 쓰레드 환경에서 하나의 데이터에 여러 쓰레드가 동시에 읽는 것을 허용하면서도 쓰기 작업은 하나의 쓰레드만 하도록
locking을 Fine-grained하게 적용했습니다. 따라서 기존의 Syncronized Collection에 비해 퍼포먼스가 좋다는 장점이 있습니다.
Fine-grained : 다수의 호출로 하나의 동일한 작업의 결과를 이루어내는 방식.
Skip List
Skip List라는 개념은 이번 신입사원 교육 중 Redis에 대한 교육에서 이미 다루었던 내용이었기에, 많은 분들이 알고 계시겠지만 다시 한번 간단히 정리해보겠습니다.
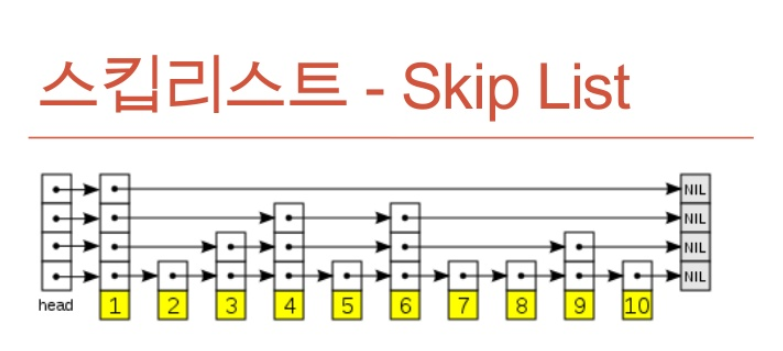
위의 그림은 Skip List를 도식화해놓은 그림입니다. Redis 교육 중 강연자 분께서 이를 급행 열차와 일반 열차에 빗대어 말씀하신 적이 있었는데, 이를 떠올리면 쉽게 이해하실 수 있을 것입니다.
상위 레벨부터 하위 레벨 순으로 각자 가지고 있는 index의 수가 다르고, value를 얻기위해 상위 레벨에서부터 오른쪽으로 움직이고, 비교를 통해 원하는 노드가 없다면 다시 아래 레벨로 노드를 찾아나가는 방식입니다.
제가 언어 능력이 부족한 관계로 잘 이해가 되지 않으실거라 생각합니다. 아마 다음 그림을 보시면 쉽게 이해 되실 것이라고 생각합니다.
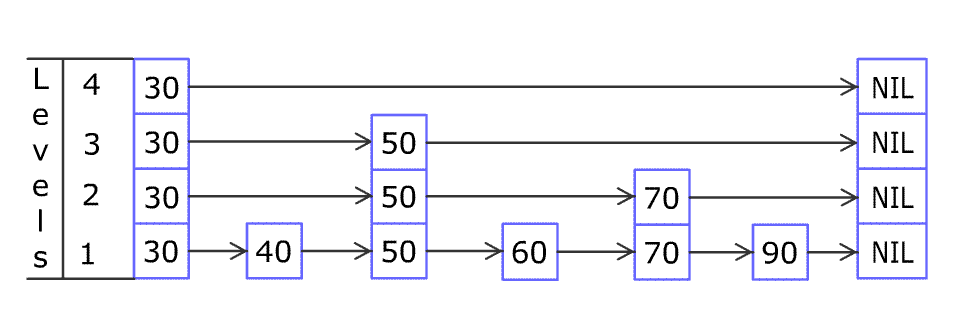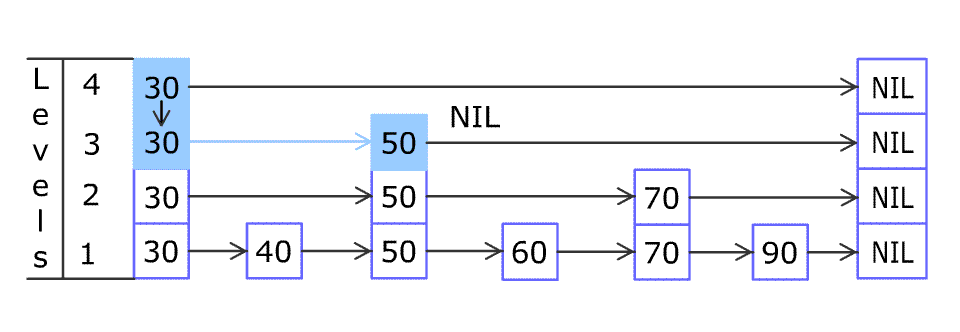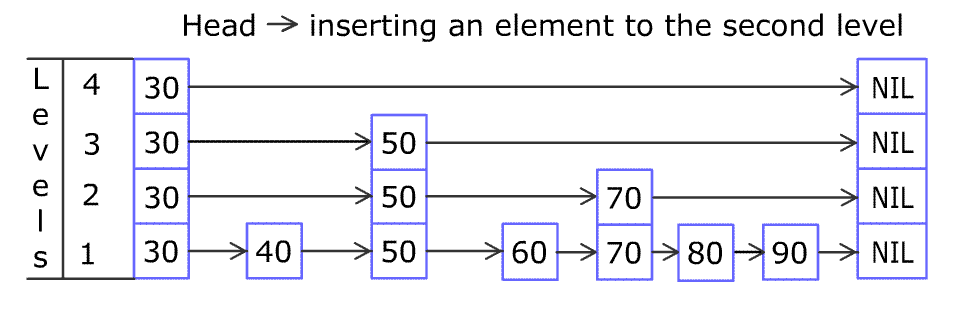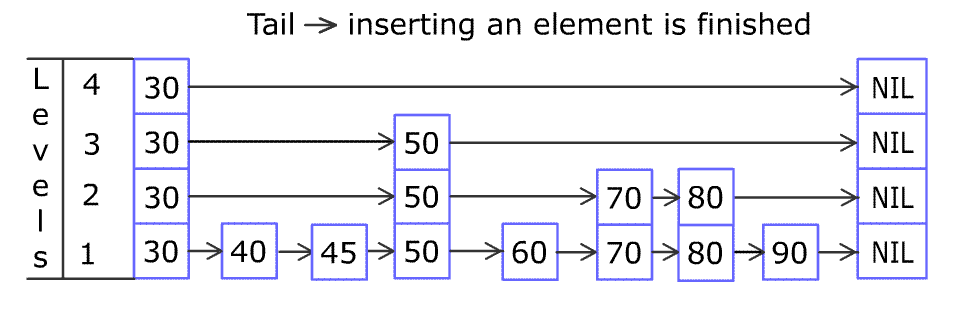
좀 더 쉽게 이해가 되셨지요? ^^
발전 과정
그럼 이제부터 본격적으로 concurrentSkipListMap가 JDK 별로 발전해 온 과정을 보도록 하겠습니다.
JDK 1.6 -> JDK 1.7
사실 concurrentSkipListMap가 JDK별로 크게 변화된 점은 많지 않습니다. 기본적으로 인덱스 추가, 값 삽입, 삭제, 레벨 낮추기, first 찾기, first entry 삭제, last 찾기, last entry 삭제, find rear 등등...
의 여러 내부 기능 코드들은 완전히 동일하거나 거의 차이가 없다고 생각하셔도 무방합니다. 많은 변화는 없었지만, 이제부터 소스를 분석하며 변화된 점들에 대해 알아보겠습니다.
먼저 JDK 1.6에서는 AtomicReferenceFieldUpdater를 사용하여 next, right value 등의 updater를 만들어 사용했지만 JDK 1.7에서는 UNSAFE라는 것을 이용합니다.
JDK 1.6
/** Updater for casNext */
static final AtomicReferenceFieldUpdater<Node, Node>
nextUpdater = AtomicReferenceFieldUpdater.newUpdater
(Node.class, Node.class, "next");
/** Updater for casValue */
static final AtomicReferenceFieldUpdater<Node, Object>
valueUpdater = AtomicReferenceFieldUpdater.newUpdater
(Node.class, Object.class, "value");
/**
* compareAndSet value field
*/
boolean casValue(Object cmp, Object val) {
return valueUpdater.compareAndSet(this, cmp, val);
}
/**
* compareAndSet next field
*/
boolean casNext(Node<K,V> cmp, Node<K,V> val) {
return nextUpdater.compareAndSet(this, cmp, val);
}JDK 1.7
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
valueOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("value"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}과연 이 둘의 차이점이 무엇인가를 찾아보았지만, 결국 둘의 기능의 거의 동일하였습니다. 둘 다 원자적 연산을 위해 사용되는 클래스라는 점에서는 완전히 동일하고, 성능상의 이유에서인지 현재의 JDK로 발전해오면서 모든 Concurrent collections에서 UNSAFE를 사용하는 것을 알 수 있었습니다. 그렇다면 잠시 UNSAFE의 대해 알아보도록 하겠습니다.
UNSAFE
sun.misc.Unsafe
Java concurrency에서 동기화를 구현하기 위해 사용하는 클래스입니다. 이는 CAS(Compare-And-Swap)을 통해 동기화를 구현합니다. 위의 소스 코드에서도 compareAndSet과 compareAndSwapObject를 볼 수 있는데,
이 둘 역시 차이점은 없다고 보면 됩니다. 웹 검색 결과, 최근에는 Compare And Swap라는 말로 이용되는 듯하고, 메모리 상에서 원자적 연산을 통해 동기화를 맞추기 위해 CPU에서 제공해주는 연산을 가리키는 말이라고 합니다.
이름이 Unsafe인 이유는 자바의 경우 프로그래머가 메모리에 직접 접근하여 이상한 실수를 하는 일이 없지만, 이를 이용하면 의도적으로 그런 실수를 할 수도 있다고 합니다. 따라서 JDK 내부적으로는 사용을 하고 있지만
안전하지 않기 때문에, Userland에서는 사용하지 않도록 권장하고 있는 api 입니다. Compare And Swap에 대해 자세히 알고 싶으시면 이 글을 참조하세요
다음은 소스를 보다가 우연치 않게 발견한 재미있는 변화입니다.
JDK 1.6
if (n != null) {
Node<K,V> f = n.next;
if (n != b.next) // inconsistent read
break;;
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}JDK 1.7
if (n != null) {
Node<K,V> f = n.next;
if (n != b.next) // inconsistent read
break;
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}변화점을 찾으셨나요? 변화점은 break 뒤에 세미콜론이 2개 붙어있던 것이 하나로 수정되었다는 점입니다. 아마도 JDK 1.6에서 개발자 분이 실수를 하신 것이 아닌가 생각되지만 재미있는 발견이라 생각했습니다. 그 외에 JDK 1.6에서 JDK 1.7로의 변화는 주석으로 달린 설명 중 sun이 oracle로 바뀌었고, 설명이 좀 더 길어졌다는 변화도 있었습니다.(어쩌면 sun이 oracle로 인수된 것이 가장 큰 변화일지도...) 앞서도 계속 언급했지만 JDK 1.6에서 JDK 1.7로의 변화점은 거의 없다고 보셔도 됩니다. 그럼 다음으로 JDK 1.7에서 JDK 1.8로의 변화 사항에 대해 알아보겠습니다.
JDK 1.7 -> JDK 1.8
JDK 1.7에서 JDK 1.8로 가면서 concurrentSkipListMap 상의 변화는 사실 엄청 많은 줄 알았습니다. 주로 Eclipse에서 지원하는 compare 기능을 이용하여 소스를 비교하였는데, JDK 1.8에서는 JDK 1.7과 메소드와 클래스들의 순서가 많이 변경되어 차이가 많이 나는 듯 보였습니다. 하지만 천천히 소스 코드를 보니 변화점이 많지는 않다는 것을 알게 되었습니다. 그럼 지금부터 변화 사항들에 대해 알아보도록 하겠습니다.
먼저 가장 눈에 띄인 것은 annotation이 많이 사용되었다는 것입니다. 아래 두 코드를 비교해보세요.
JDK 1.7
V getValidValue() {
Object v = value;
if (v == this || v == BASE_HEADER)
return null;
return (V)v;
}JDK 1.8
V getValidValue() {
Object v = value;
if (v == this || v == BASE_HEADER)
return null;
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
위 코드를 보시면 @SuppressWarnings가 사용된 것을 보실 수 있습니다. 이는 컴파일러에서 보여주는 경고메시지를 무시하기 위해서 사용하는 것이라고 알고 있는데, JDK 1.8에서는 거의 모든 경고가 나올 위치에
@SuppressWarnings이 사용되어 있습니다. 사실 평소에 경고가 나오더라도 그냥 무시하는 것이 다반사인데, 이런 점에서 JDK 1.8의 concurrentSkipListMap은 좀 더 세심하게 개발되지 않았나 싶은 생각도 들었습니다.
다음은 조금 스스로 생각하게 되는 변화를 보게 되었습니다.
JDK 1.7
int j = randomLevel();
if (j > h.level) j = h.level + 1;JDK 1.8
int rnd = ThreadLocalRandom.current().nextInt();
int j = 0;
if ((rnd & 0x80000001) == 0) {
do {
++j;
} while (((rnd >>>= 1) & 1) != 0);
if (j > h.level) j = h.level + 1;
}위의 소스 코드를 보시면 JDK 1.7에서는 랜덤한 수를 뽑기 위해 하나의 메소드로 분리하여 사용하는 것을 알 수 있습니다. 하지만 JDK 1.8에서는 랜덤 수를 뽑을 때마다 위의 코드를 반복하여 사용하고 있습니다. 이런 코드가 총 3번 반복되는데, 메소드로 빼는 것이 더 좋은 방법이 아니었나 싶은 생각도 들고, 아니면 메소드 호출에 조금이라도 성능상 손해가 있어서 이렇게 했는지는 정확히 알 수 없었습니다. 또한 위의 코드에서의 차이점은 랜덤 수를 뽑는데 사용한 방법이 조금 다르다는 것이었는데, ThreadLocalRandom은 Thread에 독립적으로 랜덤한 수를 추출해 내기위해서 JDK 1.7부터 추가된 클래스라고 합니다.
지금까지 concurrentSkipListMap의 JDK 별 발전 과정을 보았습니다. JDK 1.7에서 JDK 1.8로 변화하면서 메소드 이름과 순서가 너무 많이 바뀌어서 아직까지 변화 과정을 하나하나 다 찾아보지는 못했습니다. ㅠㅠ 좀 더 많은 시간을 가지고 JDK 1.8에서의 변화 과정을 찾는대로 계속 업데이트 해나가겠습니다. 부족한 글이지만 읽어주셔서 감사합니다.
참조
http://dontcryme.blog.me/30124306779
http://deepblue28.tistory.com/entry/Java-SynchronizedCollections-vs-ConcurrentCollections
http://rangken.github.io/blog/2015/sun.misc.unSafe/